
The Machine Learning Lifecycle
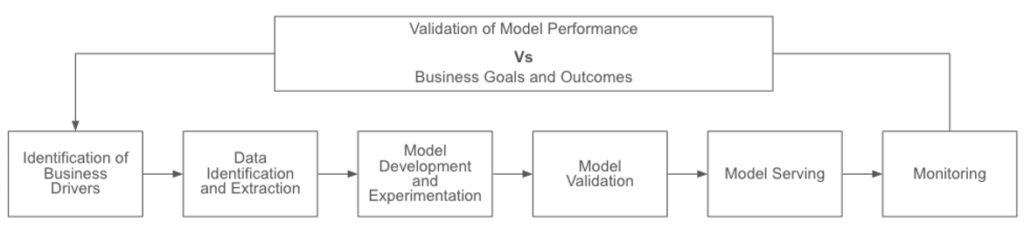
Identification of Business Drivers: This stage involves business owners looking to ML/AI as a component of new offerings, as a means to expand the reach or capabilities of existing offerings, or to increase efficiencies in an effort to improve margins.
Data Identification and Extraction: With the business need identified, data science teams will locate data that can enable training a model to make the necessary predictions. Within each data set, features will be extracted that will have the most relevance to the model’s training.
Model Development and Experimentation: This stage represents the bulk of actual development work on the part of data science teams. Engineers will iterate through various models and model parameters, arriving at a final initial version that will be tested and deployed.
Model Validation: Using a dataset independent from the prior training data, data scientists will validate the results of earlier experiments. If the predictions are in line with expectations, then the model will be approved for deployment.
Model Serving: Engineers will deploy the model, usually behind a REST API that end users or frontend services and applications can query. Models will typically reinforce their training on a continual basis with data provided to them.
Monitoring: Ongoing monitoring of the predictions served by the model will inform business owners and the data science teams that support them whether or not the model requires retraining or re-evaluation or may be subject to other underlying flaws.
A future article will examine various levels of maturity that organizations may have with respect to model development and production pipelines, e.g., the degree to which this lifecycle has automation embedded within it.
Security Considerations within the ML Lifecycle
Machine learning models, like the applications and web services that they may help power, are composed of source code, some of which is first-party developed and some developed by third-parties. And like source code with third-party packages and libraries, machine learning models may introduce security risks through insecure software supply chains and models that lack resilience to adversarial attacks against them.
Risk can also present itself before data scientists begin model development. Consider the following potential risks, by no means exclusive, in each stage and potential strategies companies can employ to mitigate them:
| Stage | Risk | Mitigation Aproaches |
|---|---|---|
| Identification of Business Drivers | Potential regulatory or legal barriers that go unnoticed | Ensure the organization has privacy, risk, and compliance functions in place to provide ongoing oversight of how machine learning is utilized and how the enterprise remains compliant with applicable statutes and regulations. |
| Misdirected use of ML/AI to address the business need | Challenge initial theories that ML/AI is the solution to a problem that may require a less costly alternative. Avoid the temptation to view every business objective as a nail that needs the ML/AI hammer. | |
| Data Identification and Extraction | Exposure of regulatory-protected information | Provide data scientists with access to the least amount of data necessary to effectively train and test models and ensure that a copy of such data has potentially sensitive information redacted or de-identified. |
| Use of potentially unnecessary data in the feature set | Validate with data scientists the minimal amount of features that they need and limit access to only that set of data. | |
| Model Development and Experimentation | Use of pre-trained models with embedded security risks |
Employ third-party commercial or open-source ML scanners to identify embedded security threats and block deployment within the model CI/CD pipeline. Encourage data scientists to avoid the use of pre-trained models from untrusted, public sources. |
| Models developed using insecure packages and libraries | Ensure that ML/AI source code is subject to the same software composition analysis (SCA) that application code must undergo. | |
| Access to source code is not governed or monitored appropriately | Review access to code repositories, limiting access where necessary based on the least privilege principle, and monitor for abnormal cloning or commit behavior. | |
| Model Validation | Model explainability is not sufficiently clear or precise enough to enable data scientists or business owners, in addition to end users, to identify when the model is not behaving according to expectations and thus enable faster identification of potential issues | In addition to satisfying other Responsible AI best practices– such as transparency, security, and avoiding harmful bias and unethical impacts–ensure that the validated model can be clearly explained in terms of how predictions are generated and what features are used in that determination. |
| Model Serving | Production code has excessive access to data storage locations | Limit the model’s access to data storage based on the least amount of privileges required. Develop monitoring alerts for abnormal account activity. |
| Excessive access to the model during runtime is granted to human and non-human users | Review access and authorizations granted to identities and refine as necessary. | |
| Insecure infrastructure and applications hosting the model | Review compliance of underlying infrastructure and applications and services that embed the model to identify security gaps and resolve them as necessary, developing processes to maintain security and compliance over time. | |
| Monitoring | Lack of effective triggers or feedback loops for model review | Continuously monitor accuracy rates and potential prediction drift and establish appropriate triggers to review or re-evaluate the model. |
| Lack of visibility into potentially malicious activity directed against ML models | Explore third-party options for monitoring ML/AI models for potentially malicious input and accordingly skewed results. | |
| Undefined response playbooks to respond to adversarial attacks | As applications and services with an ML/AI component migrate to production, ensure that incident playbooks include response options for mitigating the impact of an ML/AI-directed attack. |
Potential Costs of Deploying Insecure Models
Businesses that rely upon ML models, e.g., to drive revenue and customer engagement as well as facilitate decision-making processes such as preliminary loan approvals without addressing or mitigating the potential risks outlined above, invite far greater costs and negative impact than they would otherwise experience.
These costs include those that arise from adverse reputational impact in much the same fashion as a defaced website advertises a company’s lack of internal safeguards–consider the fallout from Microsoft’s Tay offering, from fraud incurred from business process violations due to either poorly trained models or an end user’s desire to force a favorable outcome through model poisoning; and from regulatory and compliance failures due to data privacy issues arising from models that contain security exposures that put training data at risk of disclosure.
Beyond the failure of a model itself, the loss of intellectual property via theft of a model’s source code or successful efforts to reverse engineer a model through adversarial attacks can impose significant costs as well, such as a loss of competitive advantage.
Combining the value that ML models have within an enterprise with the Security and Exchange Commission’s recent ruling on reporting on the materiality of cyber incidents, organizations must be aware of both how models impact their bottom line and how these models operate and respond to malicious activity through ongoing monitoring.
Building the Foundation
Ultimately, organizations that may lack a holistic approach for securely designing, developing, and operating machine learning models should seek to build foundational elements first, including:
- Formulating a comprehensive Responsible AI and cyber security controls framework for ML/AI that aligns with industry frameworks, such as NIST’s AI Risk Management Framework and MITRE ATLAS, and legal requirements, such as those imposed by the European Union and other governing bodies;
- Training product and application security teams on risks and threats associated with insecure machine learning such that security analysts can account for such risks in their threat models and design reviews;
- Educating data science teams on security risks associated with insecure machine learning models and potentially embedding a security champion within these teams, in much the same way security groups have integrated themselves into software development teams;
- Performing an inventory of machine learning models and adding these assets to the organization’s change management database (CMDB) or asset management platform. Relating these models to their dependent applications and business processes can help identify the blast radius of potential incidents that affect them and
- Ensuring that effective controls and technology are in place to secure code repositories and data storage locations used to house model code and data used to train and test models.
In Conclusion
As organizations embrace the expanded use of machine learning and artificial intelligence within their business processes and products, cybersecurity teams must likewise expand their understanding of threats and risks that such models introduce and be prepared to educate developers and data scientists on how to mitigate potential damage resulting from insecure model codes.
That damage can be far-reaching, ranging from empowering competitors to incurring fees and reputational loss. The basis for this organizational awareness and mitigation effort should include a risk and control framework for the secure development and operations of ML/AI that complements a broader strategy for embedding Responsible AI concepts throughout the model lifecycle.
While expertise in ML/AI concepts may be emerging, cybersecurity teams can take comfort in the lessons learned from past technology revolutions. When enterprises were racing to establish their first footprints on the Internet or adopting the cloud, cybersecurity was often catching up. It need not be this way during this current transformation when cybersecurity can embed itself now in ML/AI governance efforts, develop necessary guardrails early, and collaborate with data science teams looking to develop and deploy new capabilities.
With its team of analytics, data science, and security professionals, Infoedge has expertise and perspectives to share to aid enterprises in this journey.
We’d love to hear from you about any of the topics we covered above, and of course, we’d be happy to share more in-depth insights if you are interested. Reach out for a deeper dive into insights or to inquire about our upcoming events!
Author


 By Ty Nickel
By Ty Nickel
 By Biljana Cerin
By Biljana Cerin
 By infoedge
By infoedge